How Our App Went Down Twice in One Day And What We Learnt From It
December 19, 2025
•
8 min read

This blog post is about a real incident that happened at Jed (opens in new tab), an online event management system we’re building as a small team of developers (Joshua, Topboy, Evans, and myself). Jed makes it easy for event organizers to manage online events that require voting. We handle nominations with our in-built form builder, just like Google Forms. It supports online and USSD voting, and soon, event organizers will be able to sell tickets on our platform.
But beyond just building features, we’re also trying to grow as software engineers. As a team that started out as “just landing page devs” and “Vercel ninjas”, we made a decision: instead of relying on fully-managed platforms, we’d self-host (opens in new tab) everything. Why? When we started out, we were all students, aiming for the most cost-effective yet high-performing solution. So we chose this path because we believed that the best way to learn is to build, and sometimes break, real things. It wasn’t the smoothest path, but we’ve learnt more than any tutorial could have taught us.
The Problem
This is our honest documentation of how a small gap in our infrastructure knowledge (combined with a bit of negligence) caused major downtime and stress. It wasn’t funny at the time, but now that we’ve recovered, we want to share what happened, how we solved it, and what we’ve learnt — in the hope that someone else won’t go through the same stress as they undertake @TheDumbTechGuy’s (opens in new tab) challenge of self-hosting and managing infra the hard way. We’re also very open to suggestions, recommendations, or even corrections that can help us improve the service as we continue building.
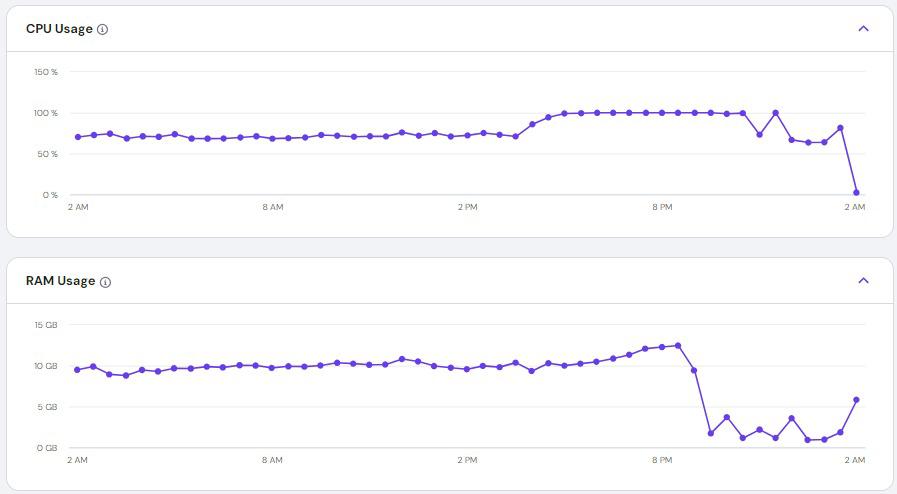
One night, our VPS (opens in new tab) started misbehaving; it just became unresponsive and all our apps were down. When we finally got access to our VPS dashboard and checked the server stats, we saw that the CPU usage had hit 200%, and it was all coming from dockerd (opens in new tab) — the Docker daemon.
Infrastructure
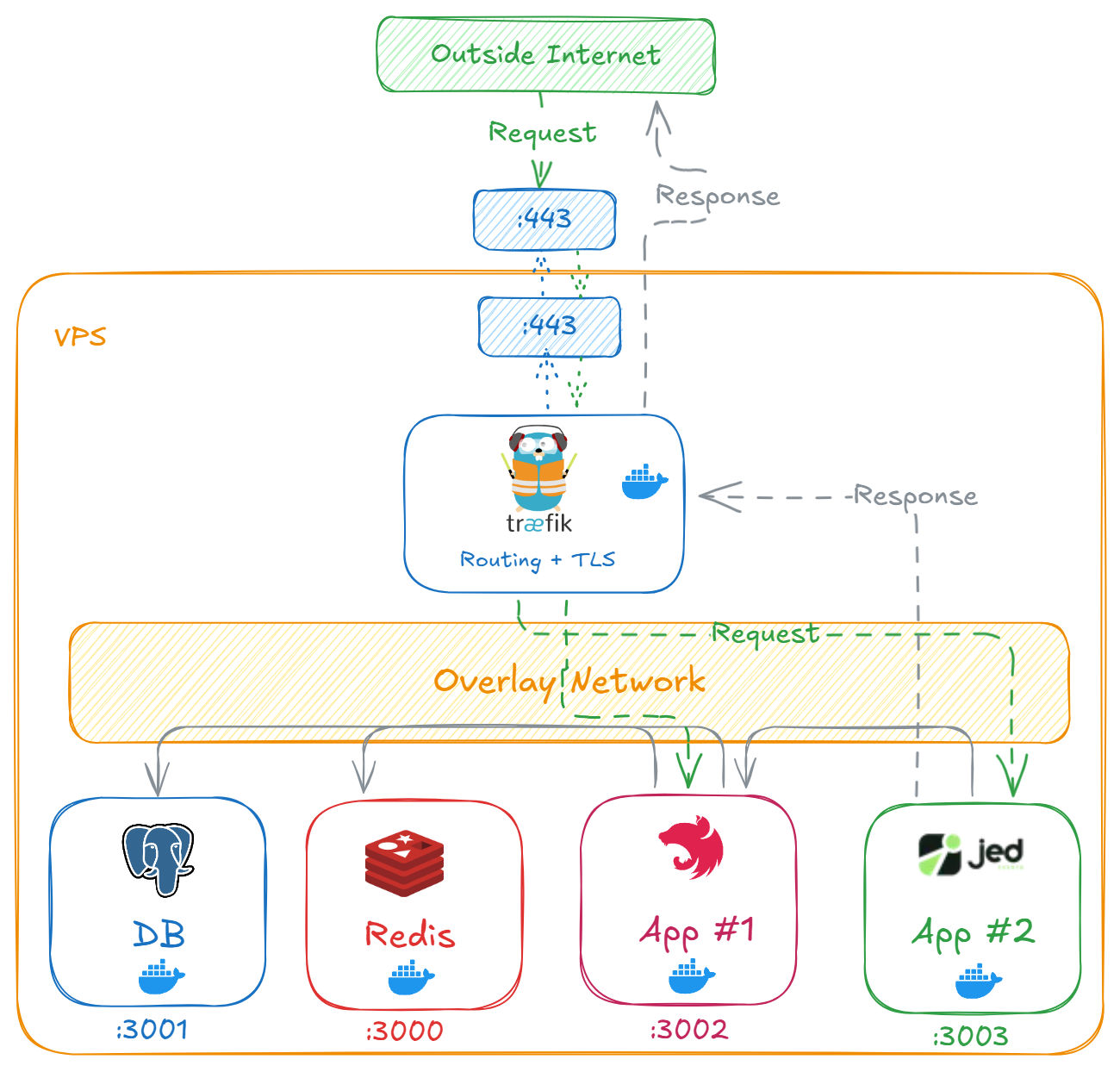
At the core of Jed’s infrastructure, we’re running a fully containerized stack on a single VPS (32GB RAM, 8 CPUs, 400GB storage). We use Docker Swarm (opens in new tab) to manage deployments across two environments(staging and production).
Inside this setup, we have three different NextJs applications: one for the landing page, another for the admin panel, and the third for the main web app where event creators manage their events. Alongside these are our NestJs backend, a separate USSD service, Redis, and a PostgreSQL database — all running as Docker containers, networked together using an overlay network (opens in new tab).
For the database, we mount a persistent volume (opens in new tab) on the host machine, so the actual database data lives outside the container lifecycle. We’ve also automated our backups — every day, our database is backed up to Amazon S3 using Dokploy's (opens in new tab) built-in tools. Dokploy provides an interface to handle backups, monitoring, and more.
All these services are managed through Docker, and we use Traefik (opens in new tab) as a reverse proxy to route traffic and handle https with Let’s Encrypt (opens in new tab). The diagram below gives a minimal view of how everything is connected.
How It Broke
The actual root cause was something very basic, but deadly: we didn’t configure our Docker deployments properly. So every time we pushed an update to GitHub, a new image was built and a new container started running without removing the old one. Over time, the duplicates piled up until there were so many containers of the frontend applications running at the same time. The negligence on our part was that we weren’t monitoring the server usage at all and we didn’t really put in much effort to find the root cause.
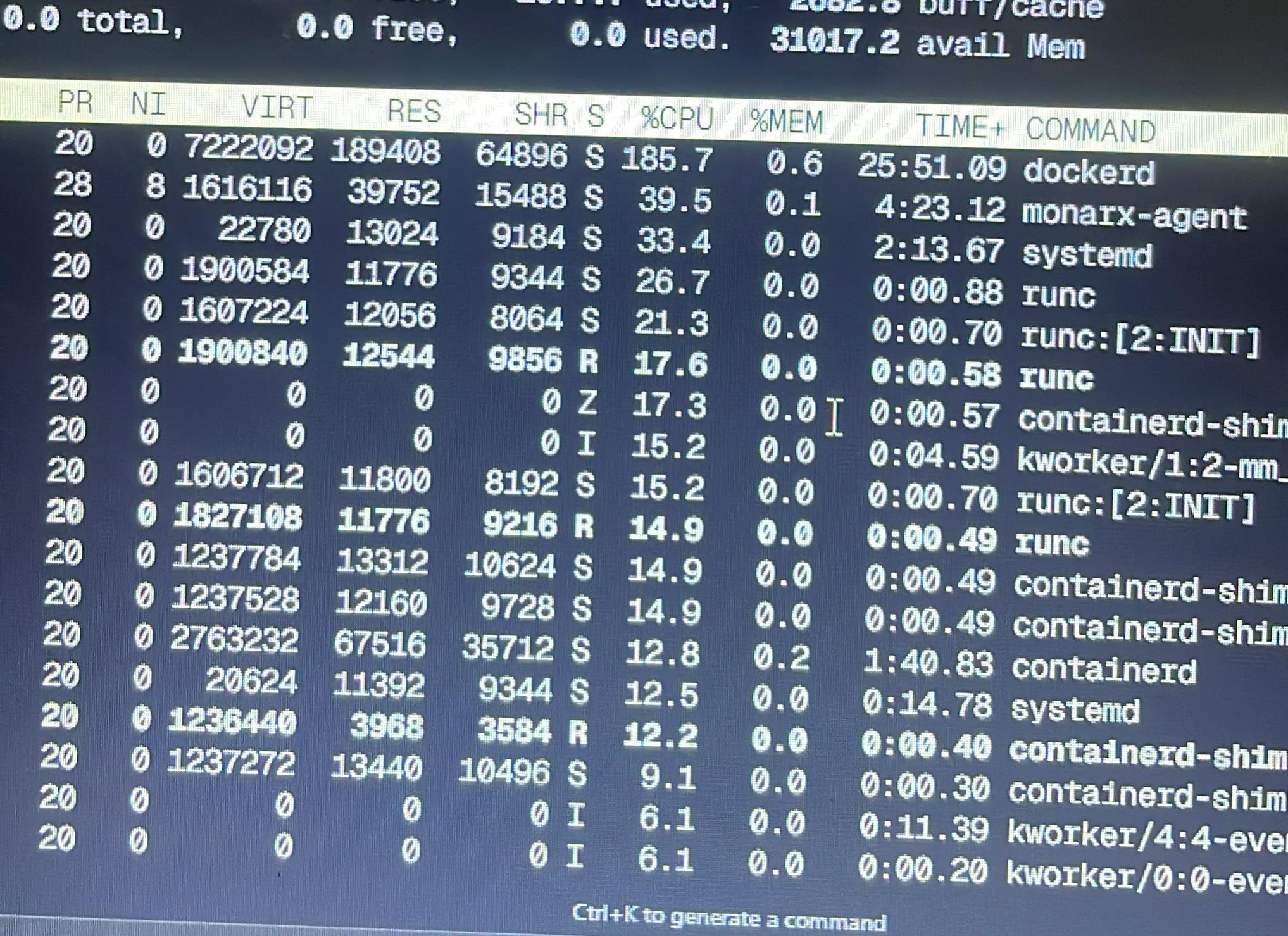
At exactly 10:01 PM on 4th July, Evans pushed a fix to the staging environment. But the deployment didn’t finish… even after 2 hours. We started suspecting something was wrong. We checked and noticed that dockerd was taking up around 185.7% of CPU. Eventually, our VPS provider put an automatic restriction on our server. All our apps went offline. Thankfully, it was late at night, so our users didn’t notice much. Still not knowing the root cause, we went into our VPS dashboard and manually removed the restriction (you're only allowed to do this once a week). Apps came back online and we went to bed.
Around 9:00 AM in the morning, we got hit again. This time, the VPS provider restricted us again — and we couldn’t override it because we had already used up our once-a-week free pass. We SSHed into the server and realized the staging landing page alone had over 20 duplicate containers running. Same for the admin app and server APIs.
Out of frustration, Topboy quickly deleted all the duplicates… which immediately fixed the CPU problem. But....
Traefik Was Gone
While deleting the containers, we accidentally deleted the Traefik configuration too. At this point, CPU usage was down (below 5%), but the apps were still down.
Topboy kept trying to fix it, thinking the VPS provider’s restriction was still active. I reached out to support, and after fighting their AI bot for hours, a real human finally told me:
“Your usage is down, and the restriction is no longer on your server. The problem might be from your end.”
So I SSHed into the server, checked container logs — everything was running fine. But no app could connect to the outside world.
Topboy managed to make Dokploy accessible via <ip-address>:3000, but not through the domain. Still in the dark, we contacted two of our big bros: Quame Jnr and BlackPrince. They helped us set up the overlay network again, but we still couldn’t access the dashboard via the domain.
Breaking Point
By 8:00 PM, we were still stuck. The only option left was to deploy everything on fly.io (opens in new tab) for our customers.At that point, Topboy just left the call out of frustration. I tried to call Declan, who was also busy hunting down some missing GHS 10 million somewhere 😅, so there was nothing we could do. While we waited for Declan, Topboy decided to calmly go through all the configs line by line. And finally… he found it. The Traefik config was missing. He quickly restored it, restarted the service, and everything came back online.

Lessons Learnt
Since that day, we’ve become a lot more careful about everything we push to production. These days, we actively monitor CPU, memory usage, and the number of running containers every day. We've also made sure our deployment process is well-structured to prevent unintentional duplication of containers. All our critical configuration files are now backed up.

The whole experience was stressful, but we’re honestly grateful. Like they say, what doesn’t kill you makes you stronger, and this one definitely prepared us better for whatever comes next.
To everyone who showed up when we needed help (Topboy, Evans, Quame Jnr, BlackPrince, Declan, and even the support rep who finally gave us a real answer) we appreciate you.
Thank you